A decade later, things finally start to click
I’m at that point in my life where, after more than 10 years in software development, a lot of things are finally starting to fall into place.
So many concepts that once felt abstract are now becoming clearer, how they work under the hood, why they were designed the way they were, and what trade-offs they carry.
While deep-diving into Span<T> and its nature, especially ref struct and the original design ideas behind it, I kept getting the same feeling I had years ago when I was learning LINQ internals for the first time.
One of my all-time favorite learning resources has always been EduLinq by Jon Skeet:
https://codeblog.jonskeet.uk/category/edulinq/
For me, it’s a classic. It was the best way to truly understand how LINQ works internally: IEnumerable, the enumerator pattern, deferred execution, and how all the pieces fit together.
After building a small Span-based wrapper and experimenting with it, my first instinct was simple:
If we can achieve such fast in-memory operations with zero allocations, why isn’t this model natively supported by the .NET framework itself?
That question sent me down a rabbit hole.
I started digging deeper. I began implementing my own LINQ-style operators on top of Span<T>. And very quickly, I realized that in many cases when everything is already in memory, operations can be done significantly faster than the traditional IEnumerable<T> model allows.
Even more importantly, most of these operations can be performed with zero allocations, which becomes crucial once you start dealing with large objects and heavy in-memory workloads.
Eventually, when you look at LINQ’s original implementation and write something like:
var sum = data.Where(x => x % 2 == 0).Sum();
you are not executing a loop immediately. You are building an iterator pipeline. LINQ is based on IEnumerable<T> and IEnumerator<T>, and every operator returns a small iterator object that represents the next stage in the chain.
Here’s a simplified sketch (not the exact runtime source):
public static class Enumerable
{
public static IEnumerable<TSource> Where<TSource>(
this IEnumerable<TSource> source,
Func<TSource, bool> predicate)
{
if (source is TSource[] array)
return new WhereArrayIterator<TSource>(array, predicate);
return new WhereEnumerableIterator<TSource>(source, predicate);
}
}
Internally, this returns an iterator object that looks like:
private sealed class WhereEnumerableIterator<T> : IEnumerable<T>, IEnumerator<T>
{
private readonly IEnumerable<T> _source;
private readonly Func<T, bool> _predicate;
private IEnumerator<T>? _enumerator;
public WhereEnumerableIterator(IEnumerable<T> source, Func<T, bool> predicate)
{
_source = source;
_predicate = predicate;
}
public T Current { get; private set; }
public IEnumerator<T> GetEnumerator()
{
_enumerator = _source.GetEnumerator();
return this;
}
public bool MoveNext()
{
while (_enumerator!.MoveNext())
{
var item = _enumerator.Current;
if (_predicate(item))
{
Current = item;
return true;
}
}
return false;
}
public void Dispose() => _enumerator?.Dispose();
object IEnumerator.Current => Current;
IEnumerator IEnumerable.GetEnumerator() => GetEnumerator();
public void Reset() => throw new NotSupportedException();
}
So while foreach over arrays and lists can be allocation-free, once you start composing LINQ operators, you’re back to iterator objects and delegate calls.
Then Sum() simply enumerates that iterator:
public static int Sum(this IEnumerable<int> source)
{
var sum = 0;
foreach (var value in source)
sum += value;
return sum;
}
Now compare that with a Span-based pipeline:
public ref struct SpanWrapper<T>
{
private readonly Span<T> _span;
public SpanWrapper(Span<T> span)
{
_span = span;
}
public int Length => _span.Length;
public ref T this[int index] => ref _span[index];
}
This can be used like this:
public static class SpanLinq
{
public static SpanWrapper<T> AsSpanWrapper<T>(this Span<T> span)
=> new SpanWrapper<T>(span);
public static SpanWrapper<T> AsSpanWrapper<T>(this List<T> list)
=> new SpanWrapper<T>(CollectionsMarshal.AsSpan(list));
public static int Sum(this SpanWrapper<int> span)
{
var sum = 0;
for (int i = 0; i < span.Length; i++)
{
sum += span[i];
}
return sum;
}
}
And we would use this as:
var list = new List<int> { 1, 2, 3, 4, 5 };
var sum = list.AsSpanWrapper().Sum();
Console.WriteLine(sum);
If you look closely at this helper, it allocates nothing on the managed heap and internally uses the CollectionsMarshal class. It gives you direct access to the backing storage of collections like List<T> with minimal overhead. This is fast, but it’s a sharp tool: the span is only valid while the list isn’t modified or resized, and it is not thread-safe.
Also, because SpanWrapper<T> is a ref struct, it is stack-only. You can’t store it on the heap, capture it in lambdas, or use it across await/yield boundaries. That’s a big reason these APIs aren’t drop-in replacements for IEnumerable<T>.
Imagine we just performed a very simple sum operation without extra allocations. Have you ever worked with huge Excel files, where loading too much data into memory can completely destroy your RAM? I have. I once worked on local processing of Excel files like this, and it took more than a day and a half to complete. Back then, I didn’t know about these kinds of in-memory data manipulation techniques, and that experience pushed me to think much more seriously about performance and memory usage.
There are so many things we could do better when processing large datasets. That’s why I started wondering:
Why not rewrite LINQ in a way that focuses on efficient, low-memory operations and filtering, so we can improve the performance of everyday data processing?
You really feel this when you’re working on things like deserialization pipelines, string-heavy processing, CSV or Excel parsing, log processing, or any kind of in-memory filtering and transformation. In those kinds of systems, every allocation matters. A few iterator objects here and there might look harmless, but under real load they turn into GC pressure.
Eventually, I discovered that around last summer a third-party library had already explored this exact direction.
On Reddit, someone asked Stephen Toub about a low-level C# library, and he pointed to one worth checking out: https://www.reddit.com/r/dotnet/comments/1ojv442/comment/nm5y4p6/
That library is called ZLinq:
https://github.com/Cysharp/ZLinq
There is a very nice article from the author himself explaining how ZLinq is implemented:
ZLinq, A Zero Allocation LINQ Library for .NET
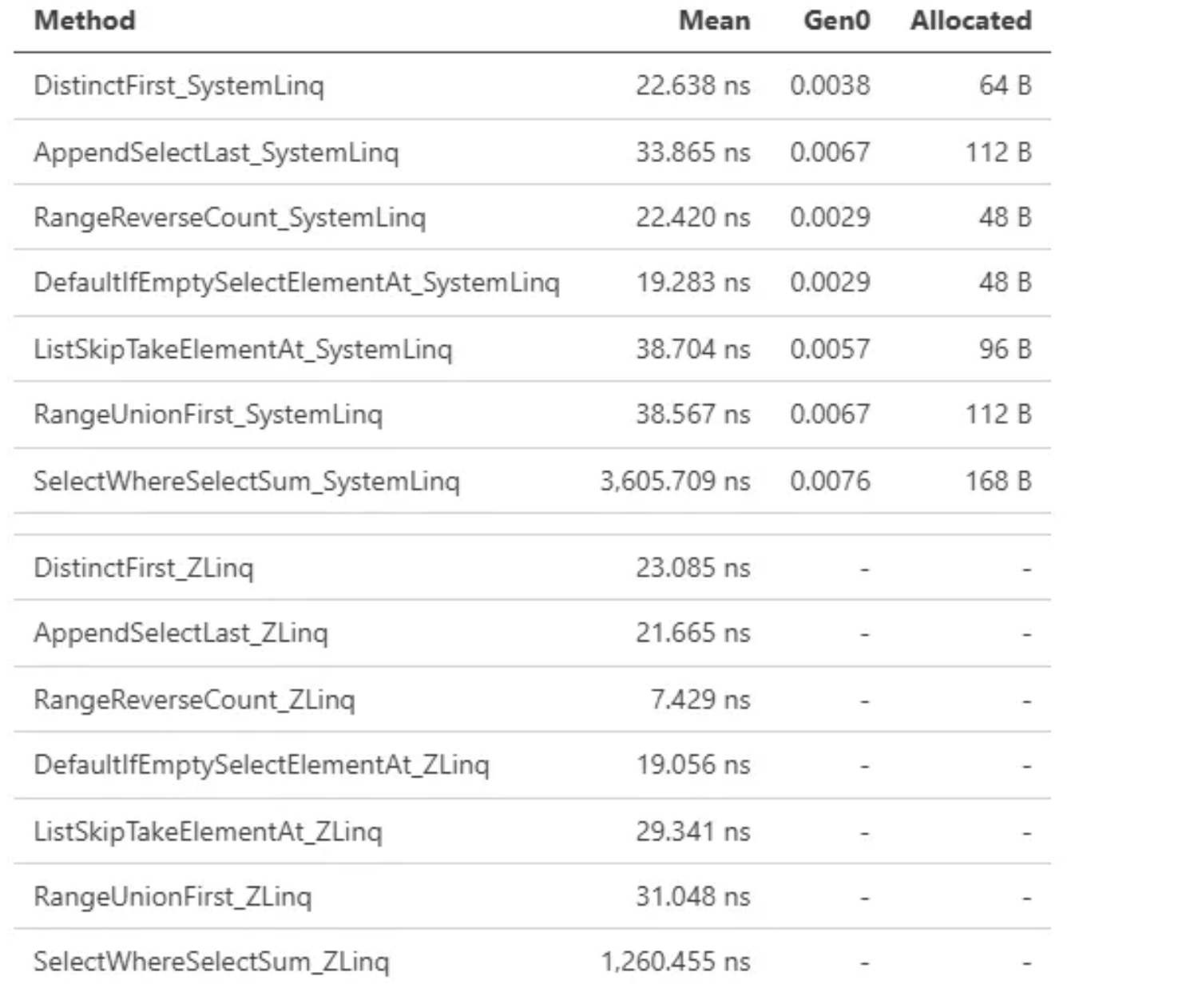
The GitHub repository also contains excellent benchmarks. You can already see the initial performance differences in this run:
ZLinq Benchmark Run
Look at this beauty. So many internal processes can be done using Span<T> integrations when implemented properly.
The library combines Span<T> pipelines with value based enumerators and static dispatch to eliminate iterator allocations and virtual calls.
That said, ZLinq is not something magical. It really shines when you’re dealing with large in-memory datasets and you care about allocations and GC pressure. If you’re working on hot paths like parsing, encoding, filtering, or numeric processing, this kind of approach can make a huge difference. It’s also great when you want predictable performance and tight loops over arrays and memory buffers.
On the other hand, it won’t magically speed things up if your bottleneck is I/O, networking, or database access. It also won’t help much in async streaming scenarios or when your data already comes through lazy IEnumerable<T> pipelines. In those cases, the performance gains are usually lost in the noise of the surrounding system.
Interesting benchmarks here:
Of course it can’t replace LINQ, but ZLinq gives us a lot of benefits, but unfortunately, since it’s still relatively new, not many developers know about it yet, especially those whose everyday work is on the CQRS side of things 😄
My personal opinion is that at some point Microsoft will either acquire this library or build something very similar directly into the framework, just like they once did with LINQ itself.
There’s also another interesting direction here that sits somewhere between classic LINQ and a full Span first approach.
Andrew Lock recently wrote a great article about making foreach over an IEnumerable<T> allocation-free by generating a specialized loop at runtime using DynamicMethod and Reflection.Emit. The idea is simple but clever: the allocation usually comes from boxing a struct enumerator when all you have is an interface-typed reference. If you can discover the concrete GetEnumerator() implementation and emit a loop that uses it directly, you can completely avoid that allocation.
What I really like about this approach is that it targets a very real world constraint. Sometimes you simply can’t change the API shape. Maybe you’re consuming a third-party library that only exposes IEnumerable<T>, or you’re writing instrumentation and don’t even know the concrete types at compile time. In those cases, a ZLinq style pipeline might not be an option but removing the allocation from enumeration can still be a meaningful win, especially on older runtimes.
Of course, this is also a sharp tool. Emitting IL at runtime adds complexity, and on modern runtimes the JIT is already getting very good at de abstracting these patterns automatically.
That said, there are a few things I personally don’t love about this approach.
Once you start going down the Reflection.Emit and DynamicMethod route, you’re clearly stepping into very advanced runtime territory. The code becomes harder to reason about, harder to debug, and much harder for the average developer to maintain. You’re no longer just writing C# you’re effectively writing IL by hand, which is powerful, but also fragile if you’re not extremely careful.
While this technique is brilliant for squeezing performance out of older runtimes and unknown API surfaces, it’s not something I’d want to see in most business applications. The added complexity can easily outweigh the benefits unless you’re truly operating on hot paths where every allocation shows up in profiling.
And with the direction the .NET runtime is going especially with de virtualization, stack allocation, and escape analysis improvements in .NET 10 some of these tricks are slowly becoming less necessary. It’s amazing engineering, but it can sometimes feel like fighting the runtime instead of working with it.
Still, as a learning exercise and a deep dive into what’s really happening under the hood, it’s absolutely fascinating.
Summary
What all of this ultimately shows is that performance in .NET is no longer just about writing “good enough” code and trusting the runtime to figure it out. The tools we have today Span<T>, value enumerators, stack allocation, escape analysis, and de-virtualization allow us to write code that is both expressive and extremely close to the bare metal.
Classic LINQ is still one of the most beautiful APIs ever designed in C#. It changed how an entire generation of developers thought about data processing. But it was designed in a different era, when memory was cheaper, GC pressure was less visible, and hardware was slower. ZLinq feels like a glimpse into what a modern LINQ could look like if it were designed today.
At the same time, approaches like Andrew Lock’s show that even when you’re stuck with IEnumerable<T>, there are still ways to push the runtime further if you really need to. Sometimes the fastest code is not about changing APIs it’s about understanding what’s actually happening under the hood.
I don’t think Span based pipelines will ever replace LINQ, and they probably shouldn’t. But for hot paths, large in-memory workloads, parsers, serializers, and data-heavy systems, they open up a whole new performance ceiling.
For me, this whole journey has been a reminder of why I love this ecosystem so much. The deeper you go, the more there is to learn and the more you realize just how much power modern .NET gives you if you’re willing to look beyond the surface.